Kubernetes Architecture

Introduction
What are containers?
Containers are an application-centric method to deliver high-performing, scalable applications on any infrastructure of your choice. Containers are best suited to deliver microservices by providing portable, isolated virtual environments for applications to run without interference from other running applications.
Containers encapsulate microservices and their dependencies but do not run them directly. Containers run container images.
A container image bundles the application along with its runtime, libraries, and dependencies, and it represents the source of a container deployed to offer an isolated executable environment for the application. Containers can be deployed from a specific image on many platforms, such as workstations, Virtual Machines, public cloud, etc.
What are container orchestrators and why use it?
Container orchestrators are tools which group systems together to form clusters where containers' deployment and management is automated at scale while meeting the requirements mentioned below. The clustered systems confer the advantages of distributed systems, such as increased performance, cost efficiency, reliability, workload distribution, and reduced latency.
- Fault-tolerance
- On-demand scalability
- Optimal resource usage
- Auto-discovery to automatically discover and communicate with each other
- Accessibility from the outside world
- Seamless updates/rollbacks without any downtime.
Examples: Kubernetes, AWS ECS, Docker Swarm
Makes things much easier for users especially when it comes to managing hundreds or thousands of containers running on a global infrastructure.
Kubernetes
Kubernetes or k8s (like pilot on a ship of containers) is an open-source container orchestrator used for automating deployment, scaling and management of containerised applications, and ensure high availability.
Kubernetes was derived from Google’s Borg and written in Go.
One of Kubernetes' strengths is portability. It can be deployed in many environments such as local or remote Virtual Machines (VMs), bare metal, or in public/private/hybrid/multi-cloud setups.
It can handle dynamic workloads efficiently by automatically distributing containers across nodes (physical/VMs) ensuring applications can scale horizontally.
You would use AWS EKS over AWS ECS to prevent vendor lock-in.
Architecture
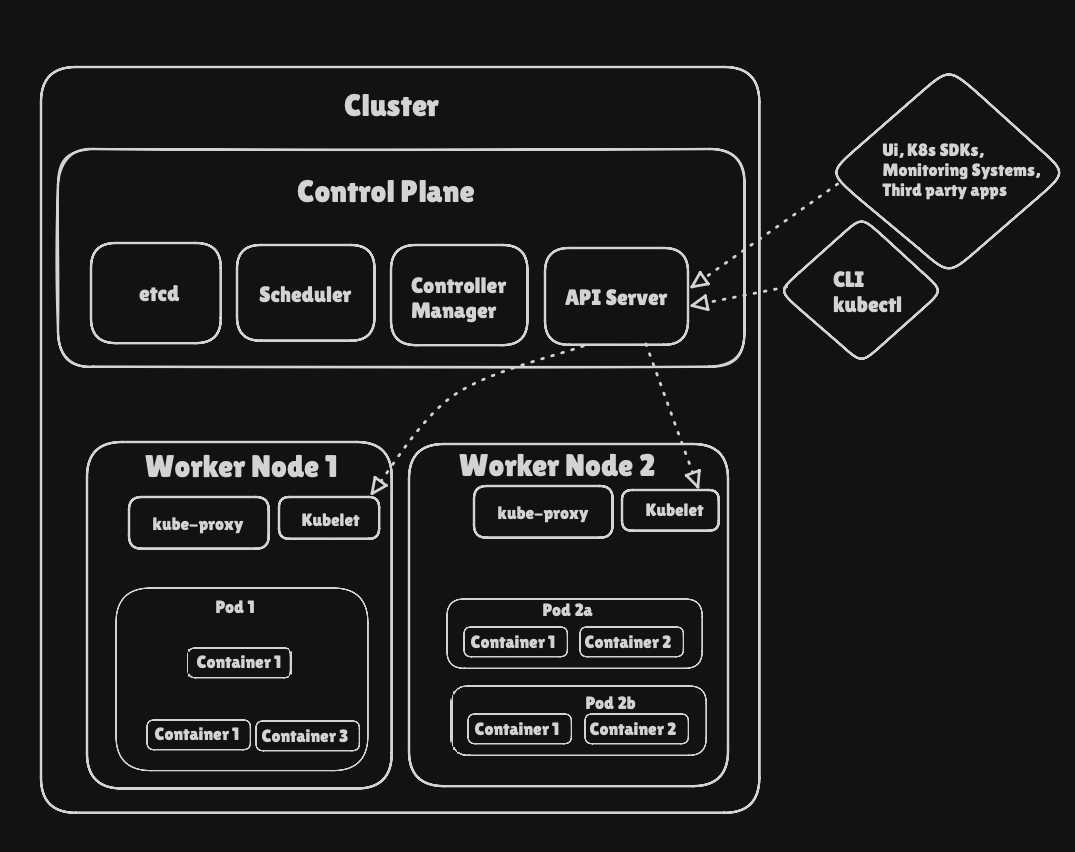
The key components are the Control Plane which manages the cluster and ensures the desired state is maintained. The Worker Nodes execute workloads, running containers inside Pods. The API server acts as a bridge between users (UI/CLI) and the cluster. Networking, storage and observability add-ons extend Kubernetes capabilities for production environments.
Control Plane
- Control Plane (CP) is considered the brain behind all the operations inside the cluster
- Provides runtime env for control plane agents responsible for managing the state of a Kubernetes cluster
- Requests are sent to CP in order to communicate with Kube clusters via CLI, UI or API
- Fault tolerance is important as losing CP will cause downtime, to ensure this CP replicas are added to the cluster (HA mode) even though only one CP actively manages the cluster
- To persist the state of the clusters, distributed key value store (etcd) is used to hold all cluster config data within CP node known as stacked topology (which is replicated too with replicas) or dedicated host aka external topology (decoupled to reduce the chances of data store loss)
- CP node runs the following components and agents:
- API server
- kube-apiserver coordinates all admin tasks
- Intercepts RESTful calls, validates and processes them
- Starts by reading the cluster’s state from key-value (kv) store and updates the state after the execution call
- It’s the only CP component that communicates with kv store, therefore acting as a middle interface for any other CP agent inquiring about state
- Highly configurable and customisable. Scales horizontally and also custom secondary API servers can be added, transforming primary as a proxy to all secondary and routing RESTful calls to them based on rules defined
- Scheduler
- kube-scheduler assigns new workload object to worker nodes
- the resource usage data for each worker nodes and workload object’s requirements such as constraints set by user or operators “disk: ssd” from kv store is retrieved via the API server
- Scheduler also takes into account Quality of Service (QoS) requirements, data locality, affinity, anti-affinity, taints & toleration, cluster topology
- Once all cluster data is available, Scheduler filters nodes that satisfies all requirements for hosting new workload
- Scheduler is highly configurable and customisable through policies, plugins and profiles
- Controller managers
- Runs controllers or operator processes that regulate the state of the k8s cluster
- Controllers are watch-loop continuously running comparing the current state (kv store via apiserver) and desired state (object’s config data). Ensures correction action if any mismatch present
- kube-controller-manager run controllers or operators that act when nodes become unavailable to ensure the container pods are as expected, to create endpoints, service accounts, and API access tokens
- cloud-controller-manager run controllers or operators that interact with underlying cloud infra when nodes become unavailable, to manage store volumes (cloud), load balancing and routing
- Key-value data stores
- etcd is an open source kv store where new data is appended on and not replaced. Obsolete data is compacted periodically to minimise the size of the data store
- Only API server can communicate with it
- etcdctl (etcd’s CLI management tool) provides snapshot save and restore capabilities in single etcd instance K8s cluster example Dev/Staging. But in Prod its important to replicate the data store in HA mode (data resilience)
- Some K8s cluster bootstrapping tools such as kubeadm provision stacked etcd CP nodes
- For data store isolation from CP, bootstrapping process can be configured for an external etcd topology (dedicated separate host), reducing chance of an etcd failure
- Both stacked and external support HA config
- etcd is based on Raft Consenses Algorithm
- Additional: container runtime, node agent (kubelet), proxy (kube-proxy), observability (dashboard, cluster-level monitoring and logging)
- API server
Worker Node
- Worker Node (WN) provide running env for client applications. These applications are microservices running as application containers encapsulated in Pods controlled by cluster Control Plane in CP node
- Pods are scheduled on worker nodes, where they find required compute, memory, storage and networking to communicate with each other and outside world
- Pods are the smallest scheduling work unit in K8s
- It is the logical collection of one or more containers scheduled together
- The collection can be started, stopped or reschedules as a single unit of work
- In Multi-node K8s cluster, the network traffic between client users and the containerised applications deployed in Pods is handled directly by the worker nodes and not routed through CP node
- WN has the following components
-
Container runtime
- K8s require container runtime on the node where a Pod and its containers are to be scheduled
- A runtime is required on each node of a K8s cluster, both CP and Worker
- The recommendation is to run K8s CP components are containers (hence the necessity of a runtime on the CP nodes)
- Supported container runtimes:
-
Node agent - kubelet
- kubelet runs on nodes, both CP and Worker, and communicates with CP
- It receives Pod definitions, primarily from the API Server, and interacts with the container runtime on the node to run containers associated with the Pod
- It also monitors the health and resources of Pods running containers
- The kubelet connects to container runtimes through a plugin based interface - Container Runtime Interface (CRI)
- The CRI consists of protocol buffers, gRPC API, libraries, and additional specifications and tools
- In order to connect to interchangeable container runtimes, kubelet uses a CRI shim, an application which provides a clear abstraction layer between kubelet and the container runtime
-
kubelet - CRI shims
-
Any container runtime that implements the CRI could be used by Kubernetes to manage containers
-
Shims are Container Runtime Interface (CRI) implementations, interfaces or adapters, specific to each container runtime supported by Kubernetes
-
Proxy - kube-proxy
- The kube-proxy is the network agent which runs on each node, control plane and workers, responsible for dynamic updates and maintenance of all networking rules on the node
- It abstracts the details of Pods networking and forwards connection requests to the containers in the Pods
- The kube-proxy is responsible for TCP, UDP, and SCTP stream forwarding or random forwarding across a set of Pod backends of an application, and it implements forwarding rules defined by users through Service API objects
- The kube-proxy node agent operates in conjunction with the iptables of the node. Iptables is a firewall utility created for the Linux OS that can be managed by users through a CLI utility of the same name. The iptables utility is available for and pre-installed on many Linux distributions
-
-
Add-ons are cluster features and functionality not yet available in Kubernetes, therefore implemented through 3rd-party plugins and services.
- DNS - Cluster DNS is a DNS server required to assign DNS records to Kubernetes objects and resources
- Dashboard - A general purpose web-based user interface for cluster management
- Monitoring - Collects cluster-level container metrics and saves them to a central data store
- Logging - Collects cluster-level container logs and saves them to a central log store for analysis
- Device plugins - For system hardware resources, such as GPU, FPGA, high-performance NIC, to be advertised by the node to application pods
-
Networking
Decoupled microservices based applications rely heavily on networking in order to mimic the tight-coupling once available in the monolithic era.
- Challenges:
- Container-to-Container communication inside Pods
- A container runtime creates an isolated network space for each container it starts
- On Linux, this isolated network space is referred to as a network namespace. A network namespace can be shared across containers, or with the host operating system.
- When a grouping of containers defined by a Pod is started, a special infrastructure Pause container is initialised by the Container Runtime for the sole purpose of creating a network namespace for the Pod. All additional containers, created through user requests, running inside the Pod will share the Pause container's network namespace so that they can all talk to each other via localhost.
- Pod-to-Pod communication on the same node and across cluster nodes
- Pods are expected to be able to communicate with all other Pods in the cluster, all this without the implementation of Network Address Translation (NAT). This is a fundamental requirement of any networking implementation in Kubernetes.
- The Kubernetes network model aims to reduce complexity, and it treats Pods as VMs on a network, where each VM is equipped with a network interface - thus each Pod receiving a unique IP address. This model is called "IP-per-Pod" and ensures Pod-to-Pod communication, just as VMs are able to communicate with each other on the same network.
- Containers share the Pod's network namespace and must coordinate ports assignment inside the Pod just as applications would on a VM, all while being able to communicate with each other on localhost - inside the Pod. Uses CNI.
- Service-to-Pod communication within the same namespace and across cluster namespaces
- External-to-Service communication for clients to access applications in a cluster
- A successfully deployed containerised application running in Pods inside a Kubernetes cluster may require accessibility from the outside world. Kubernetes enables external accessibility through Services, complex encapsulations of network routing rule definitions stored in iptables on cluster nodes and implemented by kube-proxy agents. By exposing services to the external world with the aid of kube-proxy, applications become accessible from outside the cluster over a virtual IP address and a dedicated port number.
- Container-to-Container communication inside Pods